Using .NET Aspire to Gate Traffic on Data Availability
Abstract
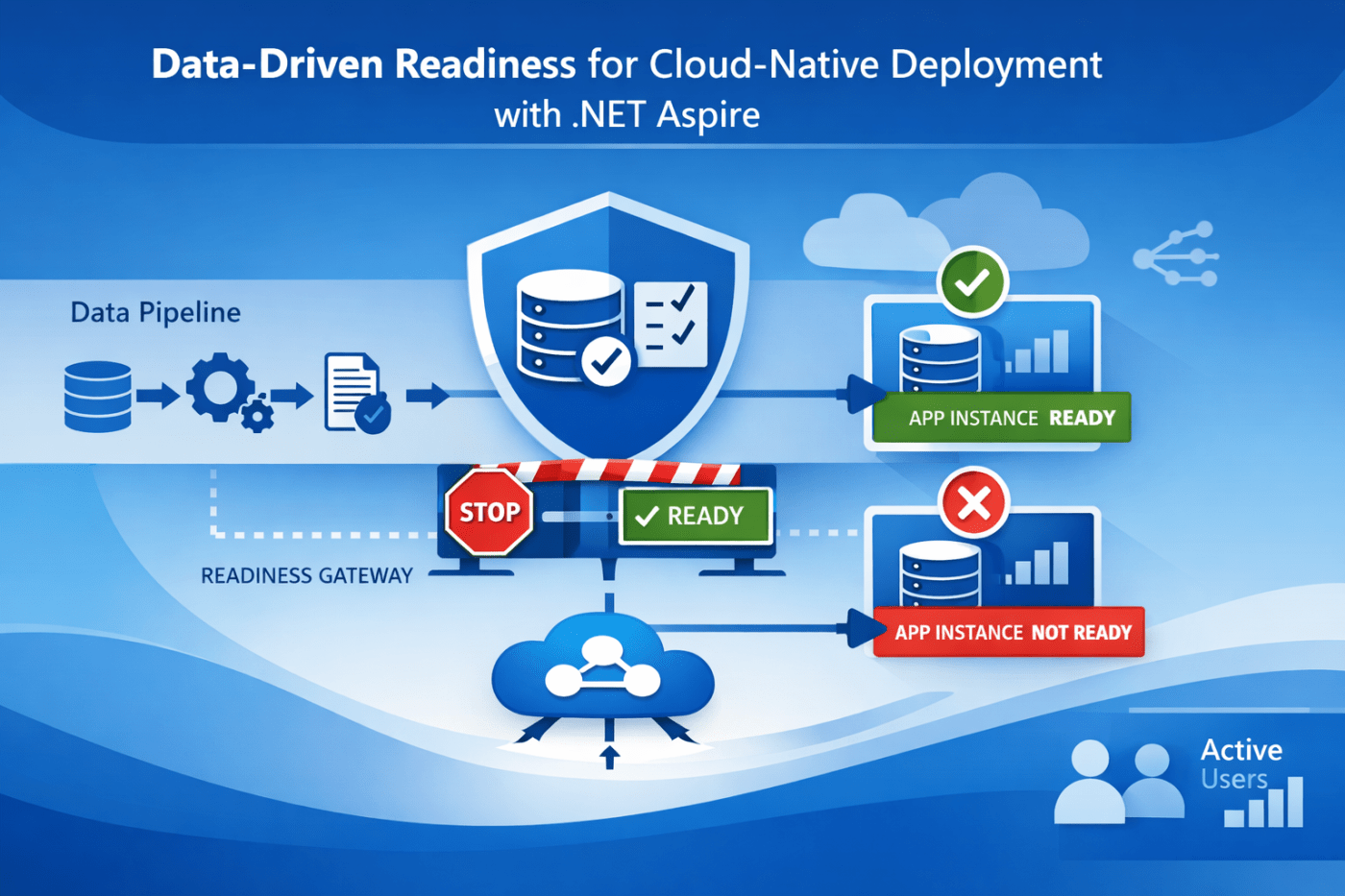
In cloud-native systems, successful deployment does not guarantee operational correctness.
Applications often start correctly, pass basic health checks, and receive production traffic — even though critical data pipelines have not completed initialization.
This article presents a data-driven readiness pattern implemented using .NET Aspire, where application instances are marked Not Ready until essential datasets are verified as available and consistent. The approach ensures that traffic is only routed to instances that can produce correct, deterministic results, not merely respond to HTTP requests.
The Problem: “Healthy” Services That Are Not Ready
Modern platforms (Azure Container Apps, Kubernetes, etc.) distinguish between:
- Liveness – Is the process alive?
- Readiness – Can the instance safely receive traffic?
In practice, many systems treat readiness as a shallow check:
- HTTP endpoint responds
- Database connection opens
- Dependency container is reachable
This breaks down for data-dependent services, such as:
- Retrieval-augmented systems
- Agent-based pipelines
- Regulatory or document-driven AI
- Index-backed APIs
If the underlying dataset is empty, stale, or partially initialized, the service may respond — but with incorrect or misleading output.
Design Principle: Readiness Is a Data Contract
We adopted a stricter rule:
An instance is “ready” only if it can answer its core questions correctly.
For data-driven systems, that means:
- Required catalogs are present
- Indexes are loaded
- Minimum dataset invariants hold
- Data freshness guarantees are satisfied
If these conditions are not met, the instance must:
- Start successfully
- Remain reachable for diagnostics
- Not receive production traffic
Implementing Data-Driven Readiness in .NET Aspire
1. Separate Liveness and Readiness Semantics
Liveness answers:
“Should this process be restarted?”
Readiness answers:
“Should traffic be routed here?”
In Aspire, readiness can be wired directly to a custom health check endpoint:
builder.Services.AddHealthChecks() .AddCheck<DataCatalogReadyHealthCheck>( "data_catalog_ready", tags: new[] { "ready" });
Only checks tagged with "ready" are evaluated by the readiness probe.
2. Encode Data Preconditions Explicitly
Instead of inferring readiness indirectly, the application evaluates domain-level invariants, for example:
- Catalog exists
- At least one active dataset version is loaded
- Dataset timestamp matches expected freshness window
Conceptually:
public HealthCheckResult CheckHealth(){ if (!catalog.Exists) return HealthCheckResult.Unhealthy("Catalog missing"); if (catalog.DocumentsLoaded == 0) return HealthCheckResult.Unhealthy("Catalog empty"); return HealthCheckResult.Healthy();}
This makes readiness observable, testable, and auditable.
Aspire Publish & Platform Integration
When using aspire publish, the generated infrastructure (e.g., Azure Container Apps) automatically maps:
/health/live→ liveness probe/health/ready→ readiness probe
The platform behavior becomes deterministic:
- Instances start
- Probes run
- Traffic is withheld until readiness passes
No custom load-balancer logic is required.
Why This Matters in Agent-Based Systems
Agent systems often appear responsive even when they are fundamentally broken:
- Empty vector indexes
- Partial ingestion
- Truncated catalogs
- Inconsistent metadata
Without readiness gating:
- Early user requests poison caches
- Non-deterministic answers leak
- Observability becomes misleading
With data-driven readiness:
- Cold starts are safe
- Scaling events are predictable
- Fail-closed behavior is enforced by design
Operational Benefits
This pattern yields several concrete benefits:
- Deterministic startup behavior
- Clear failure modes (Not Ready vs Failed)
- Zero-traffic corruption during warm-up
- Production-grade semantics for data pipelines
It also aligns cleanly with:
- GitOps workflows
- Blue/green deployments
- Scale-to-zero scenarios
Key Takeaway
Readiness is not about process health — it is about correctness guarantees.
By encoding data availability directly into readiness probes, cloud-native systems can ensure that only correct instances ever serve users.
This approach is especially critical for:
- Agent-based systems
- Regulatory or legal domains
- AI pipelines that must never “guess”
That’s all folks!
Cheers!
Gašper Rupnik
{End.}


Leave a comment