I tried to build a trustworthy Copilot agent using Copilot Studio and quickly ran into hard platform limits: inconsistent citations, non-clickable sources, and no reliable control over how answers are rendered. The experience reinforced a familiar truth: low-code works until it suddenly doesn’t.
Microsoft 365 Agents Toolkit and declarative agents exist precisely to solve this problem — and once I switched, everything clicked.
The Original Goal: A Trustworthy Copilot Agent
I started with what seemed like a straightforward goal: build a useful Copilot agent that calls custom backend logic and returns trustworthy, source-backed answers. Not a creative assistant, not a chatty helper — but an agent suitable for regulatory, policy, and compliance questions, where accuracy and traceability matter more than tone.
Naturally, I began with Copilot Studio. It promises low-code extensibility, API integration, and built-in support for sources — exactly what such an agent should need.
And at first, it worked.
But very quickly, I ran into a familiar pattern that anyone who has spent enough time with low-code platforms will recognize:
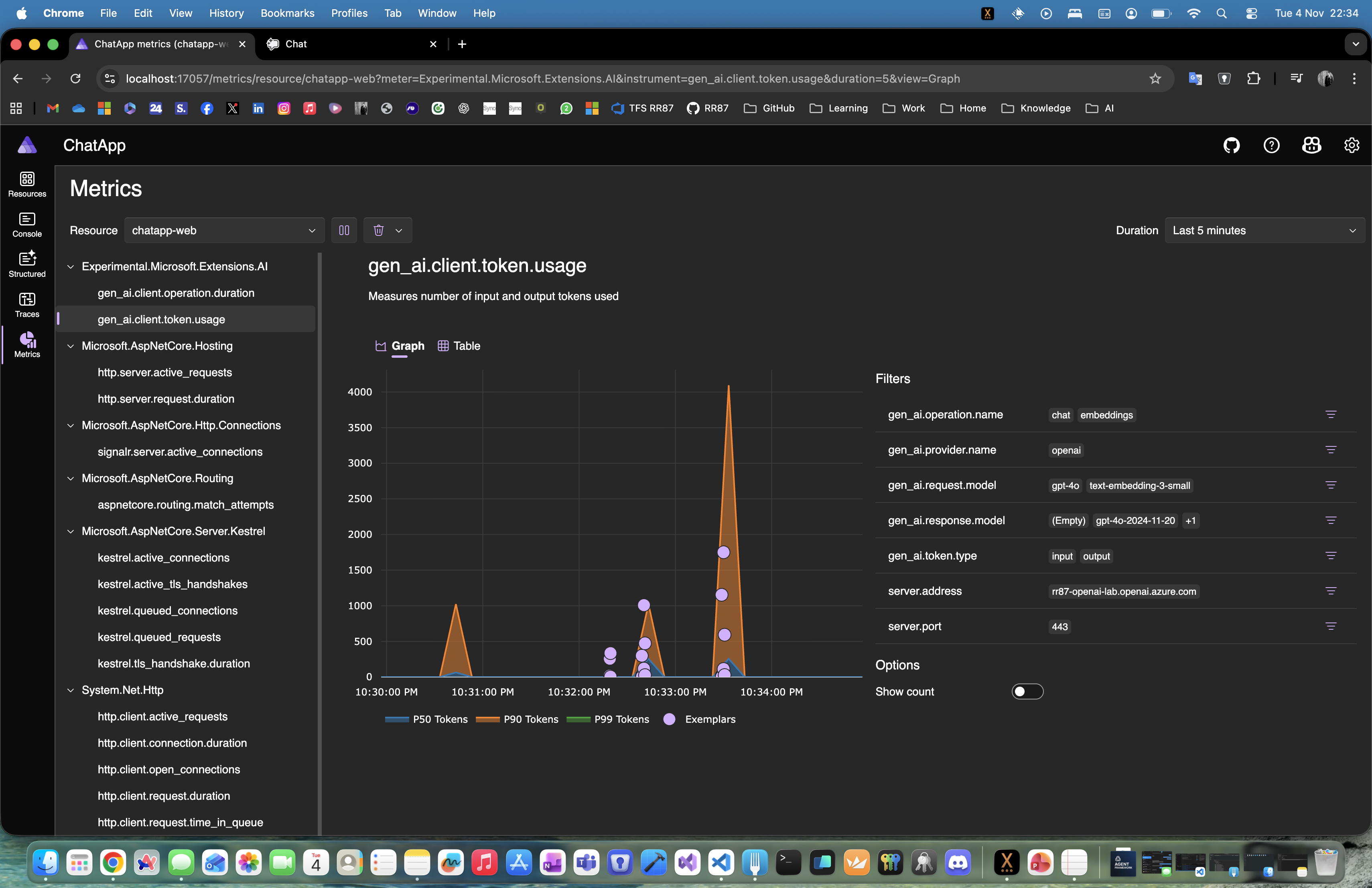
answers without sources, then answers with sources, then sources that are not clickable, then clickable sources that disappear behind a generic “Sources” button — and finally, no way to reliably control how any of this is rendered.
At that point, the problem was no longer about configuration. It was architectural.
Phase 1 – Copilot Studio: Where Things Start to Break
Copilot Studio is optimized for:
- conversational flows,
- orchestration,
- and productivity scenarios.
That becomes obvious as soon as you try to build something deterministic.
What We Implemented
- A custom Copilot action
- Calling a custom WebAPI
- Returning structured data:
{ "answer": "...", "sources": [...]}
On paper, this should be enough.
In practice, it isn’t.
Continue reading “When Low-Code Copilot Agents Hit the Wall — and Why Microsoft 365 Agents Toolkit Matters”